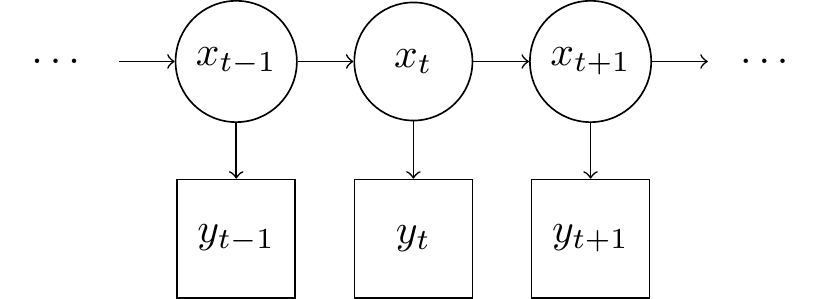
The hidden Markov model is a state-space model with a discrete latent state,
Where
The model can be visualised using a state-transition diagram where observed nodes are rectangular and latent nodes are circular. The arrows represent any transitions which can be made and also convey conditional independence assumptions in the Model. The state forms a first order Markov process, which means
Example: The occasionally dishonest casino
The casino can choose to use a fair dice, in which case the observation distribution is categorical with probabilities
We want to infer when the casino is using the loaded dice, the latent state
.$$
The observation distribution is
We can simulate data from this process by specifying values of the parameters,
- Specify the initial state of the dice,
- Simulate an initial observation conditional on the dice used,
- Simulate the next transition by drawing from a categorical distribution with probabilities corresponding to the row of the transition matrix corresponding the current state,
- Simulate an observation conditional on the state,
- Repeat 3 - 4 until the desired number of realisations are simulated
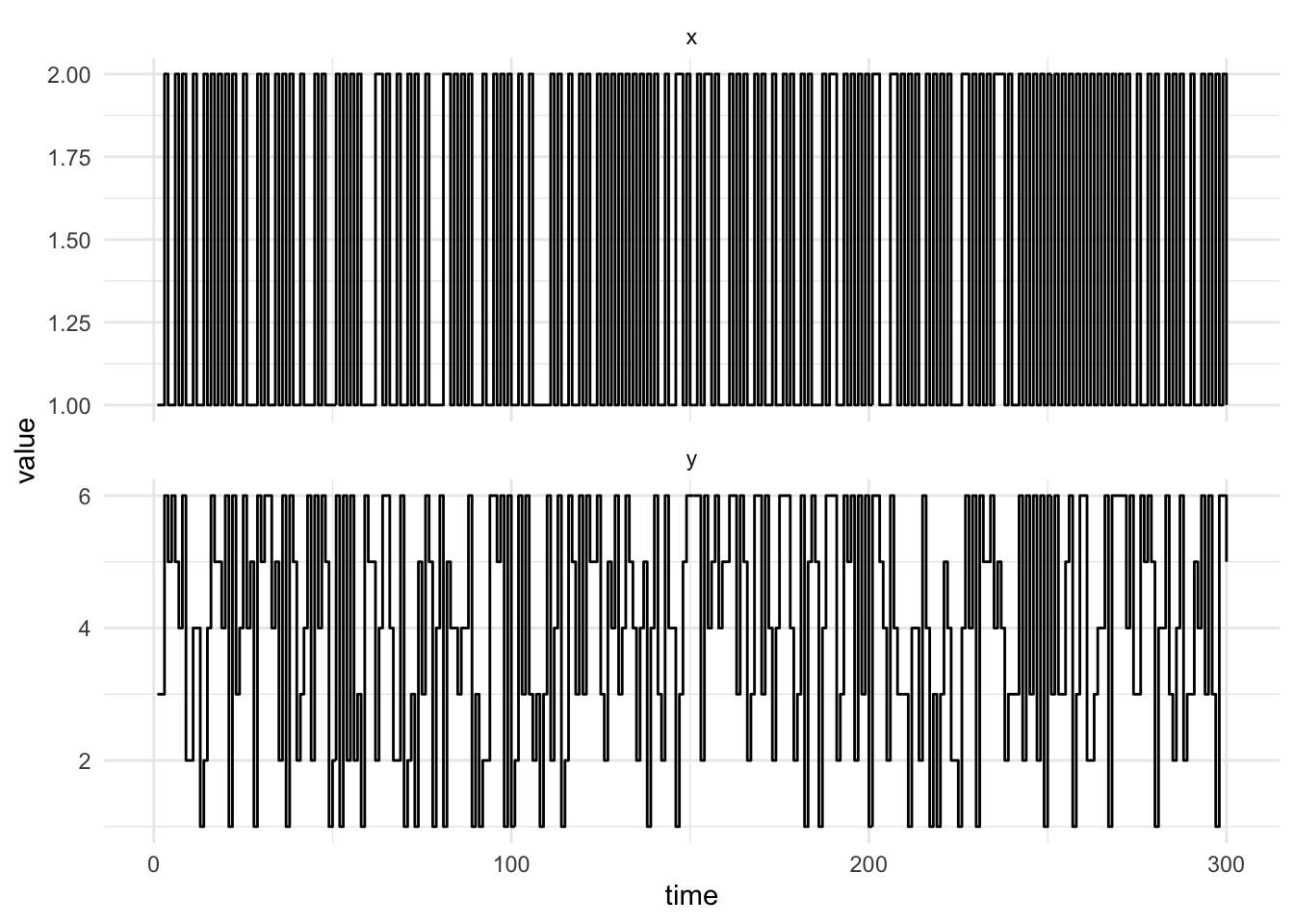
The plot below shows 300 simulations from the occasionally dishonest casino.
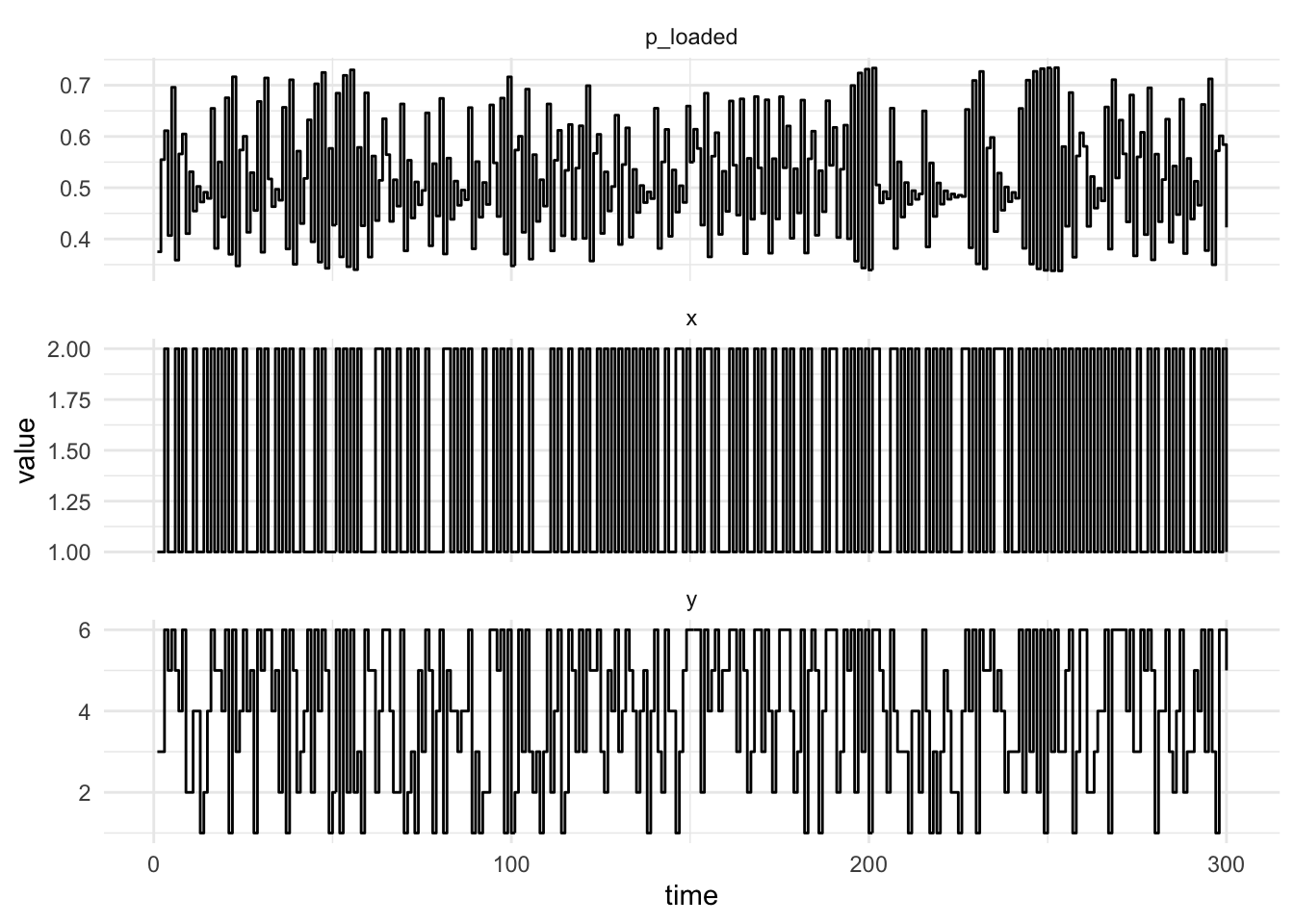
Filtering
Now we wish to identify when the casino is using the loaded dice. We can use the forward filtering algorithm. The first step of the forward algorithm is to the prediction step:
Then we observe a new value of the process
$$
Which can be calculated recursively by defining
Essentially we have use the posterior of the previous time point,
To implement the forward algorithm in R we can use a higher-order function, a fold, from the R package purrr. A higher-order function is a function which accepts a function as an argument or returns a function instead of a value such as a double or int. This might seem strange at first, but it is very useful and quite common in statistics. Consider maximising a function using an optimisation routine, we pass in a function and the initial arguments and the optimisation function and the function is evaluated at many different values until a plausible maximum is found. This is the basis of the optim function in R.
Higher-order functions can be motivated by considering a foundational principle of functional programming, to write pure functions which do not mutate state. A pure function is one which returns the same output value for the same function arguments. This means we can’t mutate state by sampling random numbers, write to disk or a database etc. Advanced functional programming languages, such as Haskell, encapsulates this behaviour in Monads. However, Monads and other higher-kinded types are not present in R. While we can’t use all the useful elements of functional programming in R, we can use some, such as higher-order functions.
One result of avoiding mutable state is that we can’t write a for-loop, since a for-loop has a counter which is mutated at each iteration (i = i + 1). To overcome this apparent obstacle we can use recursion. Consider the simple example of adding together all elements in a vector, if we are naive we can write a for-loop.
seq <- 1:10
total <- 0
for (i in seq_along(seq)) {
total = total + seq[i]
}
total[1] 55This implementation has two variables which are mutated to calculate the final results. To avoid mutating state, we can write a recursive function which calls itself.
loop <- function(total, seq) {
if (length(seq) == 0) {
total
} else {
loop(total + seq[1], seq[-1])
}
}
loop(0, 1:10)[1] 55R does not have tail-call elimination and hence this recursive function will not work with long sequences, however it does not mutate any state. We can generalise this function to be a higher-order function.
fold <- function(init, seq, f) {
if (length(seq) == 0) {
init
} else {
fold(f(init, seq[1]), seq[-1], f)
}
}Here the function fold applies the user-specified binary function f to the initial value init and the first element of the sequence. The result of applying f to these values is then used as the next initial value with the rest of the sequence. We can use this to calculate any binary reduction we can think of.
fold(1, seq, function(x, y) x * y)[1] 3628800This example is equivalent to the reduce function in purrr. purrr::reduce by default can be used to combine the elements of a vector or list using a binary function starting with the first element in the list. For instance we can calculate the sum of a vector of numbers
purrr::reduce(1:10, function(x, y) x + y)[1] 55We can also use the function shorthand provided in purrr, where function(x, y) x + y can be written ~ .x + .y.
Other arguments provided to the reduce function can change its behaviour such as reversing the direction by changing the .direction argument (which will not affect the above computation, since addition is associative, ie. .init) to the computation, instead of starting with the first (or last) element of the list.
purrr::accumulate is similar to reduce, however it does not discard intermediate computations.
purrr::accumulate(1:10, `+`) [1] 1 3 6 10 15 21 28 36 45 55Hence, if we change the direction this will change the output.
purrr::accumulate(1:10, `+`, .dir = "backward") [1] 55 54 52 49 45 40 34 27 19 10These functions can appear strange at first, however they don’t suffer from common problems such as off-by-one errors when writing a for-loop with indexing.
The accumulate function can be used to write the forward algorithm by first writing a single step in the forward algorithm. The function forward_step accepts the current smoothed state at time t-1, alpha, and the observed value at time t, y. The arguments observation and P represent the observation distribution and the transition matrix respectively and remain constant in this example
forward_step <- function(alpha, y, observation, P) {
normalise(observation(y) * t(P) %*% alpha)
}The forward algorithm can then be written using the accumulate function by first calculating the initial value of alpha and using this as the value .init then the function forward_step is used with the values of observation and P set. accumulate then takes uses the initial value, .init and the first value of the observations, ys (technically the second since we use the first to initialise alpha) to produce the next alpha value. This new alpha value is passed to the next invocation of forward_step along with the next observed value and so on until the observation vector is exhausted.
forward <- function(ys, x0, observation, P) {
alpha <- normalise(observation(ys[1]) * x0)
purrr::accumulate(
ys[-1],
forward_step,
observation = observation,
P = P,
.init = alpha
)
}We assume that the dice used for the initial roll can be either loaded or fair with equal probability.
Parameter inference
We can calculate the log-probability of the evidence using the forward algorithm, this is the sum of un-normalised filtering distribution
This can be used in a Metropolis-Hastings algorithm to determine the posterior distribution of the parameters in the transition matrix,
ll_step <- function(state, y, observation, P) {
unnorm_state <- observation(y) * t(P) %*% state[[2]]
list(
state[[1]] + sum(log(unnorm_state)),
normalise(unnorm_state)
)
}To return only the log-likelihood we can use purrr::reduce.
log_likelihood <- function(ys, x0, observation, P) {
alpha <- normalise(observation(ys[1]) * x0)
init <- list(0, alpha)
purrr::reduce(ys, function(x, y) ll_step(x, y, observation, P), .init = init)[[1]]
}We can use this marginal-likelihood in a Metropolis-Hastings algorithm. We define the prior on the parameters of the transition matrix to be independent Gamma distributions with shape,
The proposal distribution is a normal centered at the un-constrained value of the parameter. We use the logit function to transform
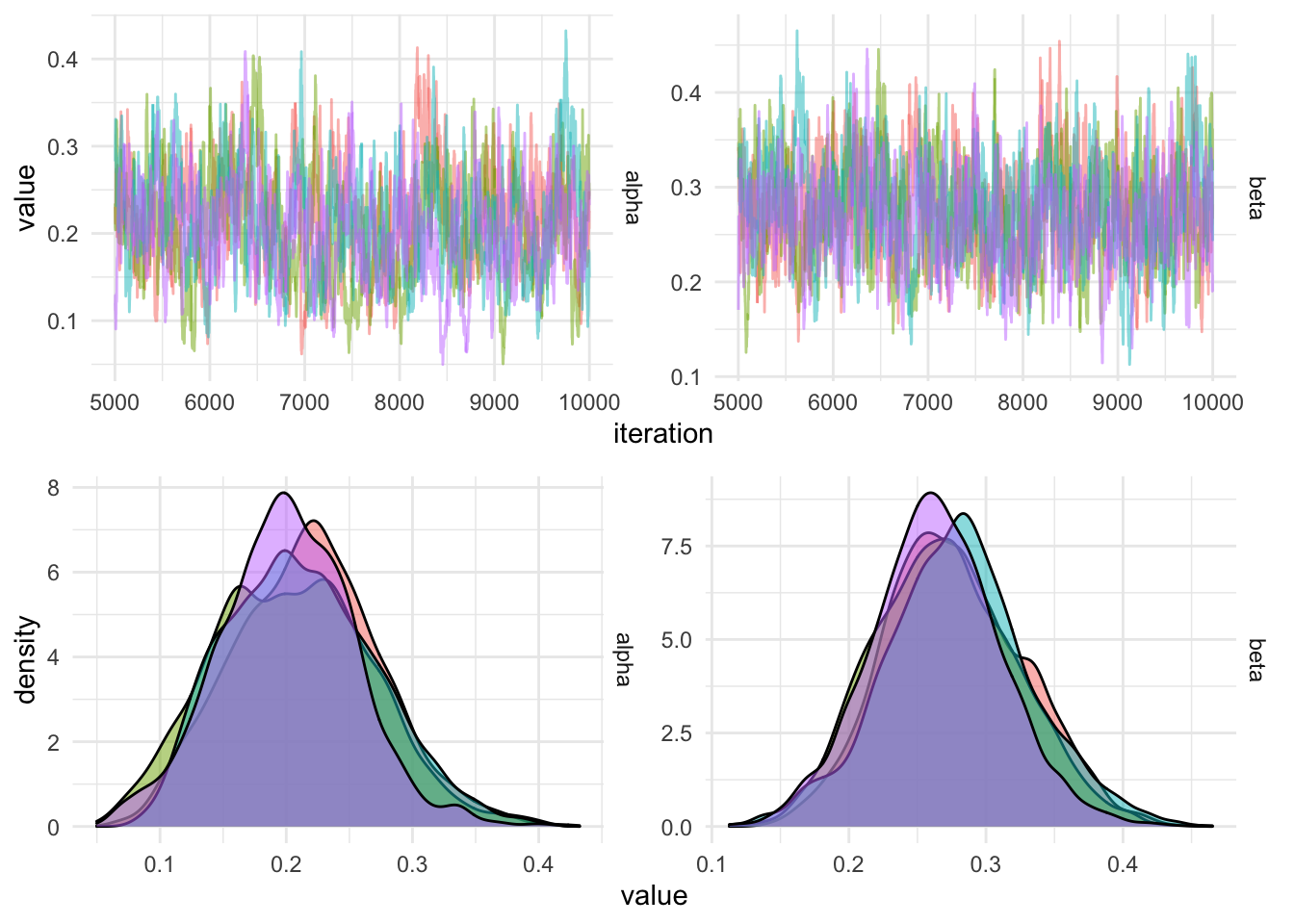
We draw 10,000 iterations from the Metropolis algorithm, the parameter diagnostics are plotted below.